
lurkertech.com → Lurker's Guide → All About Video Fields
All About Video Fields
By Chris Pirazzi. Many thanks to those who have provided valuable review and historical perspective, including Bob Williams, Bruce Busby, Scott Pritchett, and Paul Spencer.| Support This Site | If you have enjoyed this site, here are a few ways that you can help me get time to expand it further: |
 | donate now Use your credit card or PayPal to donate in support of the site. |
 | Use this link to Amazon—you pay the same, I get 4%. |
 | Learn Thai with my Talking Thai-English-Thai Dictionary app: iOS, Android, Windows. |
 | Experience Thailand richly with my Talking Thai-English-Thai Phrasebook app. |
 | Visit China easily with my Talking Chinese-English-Chinese Phrasebook app. |
 | I co-authored this bilingual cultural guide to Thai-Western romantic relationships. |
If you have enjoyed this site, here are a few ways that you can help me get time to expand it further:
| Submit This Site | Like what you see? Help spread the word on social media: | |||
| ||||
Like what you see?
Help spread the word on social media:
Table of Contents
- Introduction
- What the Heck is a Field?
- Why Do I Care?
- You Mean It Matters for Output Too?
- How Do I Show Video on the Graphics Screen?
- It's Not Even That Simple
- Other Types of "Fields"
- How Do I Interleave My Fields?
- Field Dominance
- Fields, Dominance, and Timecode Signals
- More Fun With Fields: 3:2 Pulldown
- Thoroughly Ambiguous: Avoid The Terms "Even" and "Odd"
Introduction
Most of the major video systems used in the world today, including virtually all of the standard definition systems (e.g. 480i (e.g. NTSC), 576i (e.g. PAL and SECAM), and all their digital counterparts) and many of the new HDTV formats (e.g. 1080i but not 720p and not 1080/24p) are field-based (aka interlaced or interleaved), not frame-based (aka progressive-scan).Whenever you deal with video on a computer, it is absolutely crucial that you understand a few basic facts about fields. Correctly dealing with fields in software is tricky; it is fundamentally different than dealing with plain ol' graphics images. This document explains many of these basic concepts.
To simplify our presentation, this document will use only 60M field per second systems as examples (i.e. the systems popular in the USA and Japan, which have 60M=60/1.001 fields per second, which by the way is not equal to 59.94). But everything we say here applies equally strongly to the 50 field per second signals popular in Europe and most of the rest of the world.
In this document, we use the following terminology:
- We use video to mean a television signal that is captured with a TV camera, edited with video hardware or video editing applications, and output using a TV (a video monitor). In this document, we will be discussing field-based (aka interlaced or interleaved) video systems. Modern computers input and output video signals via specialized video hardware that is separate from the graphics hardware, using video-specific interconnects such as composite, component, s-video, DV, SDI, HD-SDI, etc. In most cases, software inputs and outputs video with specialized APIs like Video for Windows, DirectShow, QuickTime, etc.
- We use graphics to mean the signal that feeds your computer monitor (your graphics monitor) that displays your desktop. Graphics is driven by a graphics adapter and is pretty much an output-only phenomenon. A graphics signal generally gets to the monitor with a VGA or digital flat panel connector. The vast majority of graphics signals are frame-based (aka progressive scan). Applications output graphics signals with APIs such as Win32, GDI, OpenGL, Direct3D, DirectDraw, etc.
What the Heck is a Field?
We programmers like to think of video as a series of frames. Each frame, we imagine in our pleasant dreams, consists of one whole image, say 640x480 pixels, all snapped at a single instant of time, and we like to believe there are, say, 30 of these images per second. To play back the video, we just display one image after the other, at 30 images per second. This is known as frame-based video (aka progressive scan).Alas, most video systems, are field-based (aka interlaced or interleaved).
Briefly put, instead of storing, say, 30 640x480 images per second, a field-based video system stores 60 640x240 images per second (actually it's 60M but we will omit the M for this section only to help our explanation), and each image has only half of the lines of the complete picture. These "half-height" images are called fields. The first field has one set of picture lines (say, line 0, 2, 4, ...) and the second field has the other set of lines (say, line 1, 3, 5, ...).
Many computer types think of fields as simply a weird way to lay out the lines of a picture in memory. They are more than that.
A field is a set of image data all of which was sampled at the same instant of time.* Each field in a video sequence is sampled at a different time, determined by the video signal's field rate. This temporal difference between all fields, not just fields of different frames, is what makes dealing with fields so tricky.
An illustration. Imagine you have a film camera that can take 60 pictures per second. Say you use that camera to take a picture of a ball whizzing by the field of view. Here are 10 pictures from that sequence:

To make it easier to visualize, we're also assuming that this magical ball changes color as it moves.
The time delay between each picture is a 60th of a second, so this sequence lasts 1/6th of a second.
Now say you take a modern* NTSC (or DV, or D1, or US-standard 1080i HD) video camera and shoot the same sequence. We all know that NTSC video is 60 (actually 60M) fields a second, so you might think that the video camera would record the same as the above. This is incorrect. The video camera does record 60 images per second, but each image consists of only half of the scanlines of the complete picture at a given time, like this:

The data captured by the video camera does not look like this:

and it does not look like this:

In reality,
- the odd-numbered images contain one set of lines,
- the even-numbered images contain the other set of lines, and
- no two images are captured at the same instant of time,

The harsh reality of video is that in any video sequence, you are missing half of the spatial information for every temporal instant. This is what we mean when we say "video is not frames." In fact, the notion of video as "frames" is something we computer people made up so as not to go insane—but sooner or later, we have to face the fact...
Why Do I Care?
Why is this an issue for those of us writing video software?Say you want to take a video sequence which you have recorded (perhaps as uncompressed, or perhaps as JPEG-compressed data) and you want to show a still frame of this sequence. A still frame would require a complete set of spatial information at a single instant of time, and so the data is simply not available to do a still frame correctly. One thing that much of our software does today to deal with this problem (and this is often done without knowledge of the real issue at hand), is to choose two adjacent fields from which to grab each set of lines. This technique has the rather ugly problem shown here:

No matter which pair of fields you choose, the resulting still frame looks quite bad. This artifact, known as "tearing" or "fingering," is an inevitable consequence of putting together an image from bits of images snapped at different times. You wouldn't notice the artifact if the fields whizzed past your eye at field rate, but as soon as you try and do a freeze frame, the effect is highly visible and bad. You also wouldn't notice the artifact if the objects being captured were not moving between fields.
There's another thing about these fingering artifacts which we've often ignored in our software—they are terrible for most compressors. If you are making still frames so that you can pass frame-sized images on to a compressor, you definitely want to avoid tearing at all costs. The compressor will waste lots of bits trying to encode the high-frequency information in the tearing artifacts and fewer bits encoding your actual picture. Depending on what size and quality of compressed image you will end up with, you might even consider just sending every other field to the compressor, rather than trying to create frames that will compress well.
Another possible technique for producing still-frames is to choose some field and double the lines in that field:

As you can see, this looks a little better, but there is an obvious loss of spatial resolution (ie, there's lots of jaggies and vertical blockiness now visible. To some extent, this can be reduced by interpolating adjacent lines in one field to get the lines of the other field:

But there is also a more subtle problem with any technique that uses one field only, which we'll see later.
There are an endless variety of more elaborate tricks you can use to come up with good still frames, all of which come under the heading of "de-interlacing methods." Some of these tricks attempt to use data from both fields in areas of the image that are not moving (so you get high spatial resolution), and double or interpolate lines of one field in areas of the image that are moving (so you get high temporal resolution). Many of the tricks take more than two fields as input. Since the data is simply not available to produce a spatially complete picture for one instant, there is no perfect solution. But depending on why you want the still frame, the extra effort may well be worth it.
You Mean It Matters for Output Too?
Yup, afraid so. When a CRT-based video monitor (a television monitor) displays interlaced video, it doesn't flash one frame at a time on the screen. During each field time (each 60th of a second (techically, 60M)), the CRT beam scans and lights up the phosphors of the lines of that field only. Then, in the next field interval, the CRT lights up the phosphors belonging to the lines of the other field. So, for example, at the instant when a pixel on a given picture line is refreshed, the pixels just above and below that pixel have not been refreshed for a 60th of a second, and will not be refreshed for another 60th of a second.LCD video monitors behave similarly: they only update half the pixels of the screen for each field period.
So if that's true, then how come images on a video monitor don't flicker hideously or jump up and down as alternate fields are refreshed?
This is partially explained by the persistence of the phosphors on a CRT screen (or the continuous glowing of pixels on an LCD monitor). Once refreshed, the lines of a given field start to fade out slowly on a CRT (or not at all on an LCD monitor), and so the monitor is still emitting some light from those lines when the lines of the other field are being refreshed. The lack of flicker is also partially explained by a similar persistence in your visual system.
Unfortunately though, these are not the only factors. Much of the reason why you do not perceive flicker on a video screen is that good-looking interlaced video signals themselves have built-in characteristics (most of which came from the camera that captured the video) that reduce the visibility of flicker.
It is important for you, as a video software writer, to understand these characteristics, because when you synthesize images on a computer or process digitized images, you must produce an image that also has these characteristics. An image which looks good on a non-interlaced graphics monitor can easily look abysmal on an interlaced video monitor.
Disclaimer: a complete understanding of when flicker is likely to be perceivable and how to get rid of it requires an in-depth analysis of the properties of the phosphors of a particular monitor (not only their persistence but also their size, overlap, and average viewing distance), it requires more knowledge of the human visual system, and it may also require an in-depth analysis of the source of the video (for example, the persistence, size, and overlap of the CCD elements used in the camera, the shape of the camera's aperture, etc.). This description is only intended to give a general sense of the issues.
Disclaimer 2: standard definition analog video (NTSC and PAL) is fraught with design "features" (bandwidth limitations, etc.) which can introduce many similar artifacts to the ones we are describing here into the final result of video output from a computer. These artifacts are beyond the scope of this document, but are also important to consider when creating data to be converted to an analog video signal. Examples of this would be antialiasing (blurring!) data in a computer to avoid chroma aliasing when the data is converted to analog video.
Here are some of the major gotchas to worry about when creating data for video output:
Abrupt Vertical Transitions: One-Pixel-High Lines
First of all, typical video images do not have abrupt vertical changes. For example, say you output an image that is entirely black except for one, one-pixel-high line line in the middle.
Since the non-black data is contained on only one line, it will appear in only one field. A video monitor will only update the image of the line 30M times a second, and it will flicker on and off quite visibly.
You can see this yourself if your computer is equipped with a video output that can display the contents of your desktop. Plug in a video monitor, make sure this webpage is visible on the video monitor, and then go into your video hardware's control panel and disable all forms of "flicker filter" (in Windows, this option is often buried inside the Display control panel, Settings tab, Advanced button, inside one of the tabs specific to your hardware vendor, but you may also find it in other Windows control panels).
You do not have to have a long line for this effect to be visible: thin, non-antialiased text exhibits the same objectionable flicker.
Typical video images are more vertically blurry; even where there is a sharp vertical transition (the bottom of an object in sharp focus, for example), the method typical cameras use to capture the image will cause the transition to blur over more than one line. It is often necessary to simulate this blurring when creating synthetic images for video.
Abrupt Vertical Transitions: Two-Pixel-High Lines
You might think one solution would be never to output single-pixel-high lines. Ok, how about changing the image above so that it has a two-pixel-high line?
These lines would include data in both fields, so part of the line is updated each 60th (technically, 60M) of a second. Unfortunately, when you actually look at the image of this line on a video monitor (again without any "flicker filter"), the line appears to be solid in time, but it appears to jump up and down, as the top and bottom line alternate between being brighter and darker.
Flicker Filter
The severity of both of these effects depends greatly on the monitor and its properties, but you can pretty much assume that someone will find them objectionable. One partial solution is to vertically blur the data you are outputting. Turning on the "flicker filter" option to most video output cards causes the hardware to vertically prefilter the screen image. This noticeably improves (but does not remove) the flickering effect.There is no particular magic method that will produce flicker-free video. The more you understand about the display devices you care about, and about when the human vision system perceives flicker and when it does not, the better a job you can do at producing a good image.
Synthetic Imagery Must Also Consist of Fields
When you modify digitized video data or synthesize new video data, the result must consist of fields with all the same properties—temporally offset and spatially disjoint. This may not be trivial to implement in a typical renderer without wasting lots of rendering resources (rendering 60M images a second, throwing out unneeded lines in each field) unless the developer has fields in mind from the start.You might think that you could generate synthetic video by taking the output of a frame-based renderer at 30M frames per second and pulling two fields out of each frame image. This will not work well: the motion in the resulting sequence on an interlaced video monitor will noticeably stutter, due to the fact that the two fields are scanned out at different times, yet represent an image from a single time.
It's exactly parallel to the correct and incorrect interpretations of how a camera records interlaced video from our section above. You should generate 60M temporally distinct fields per second, like this:

You should not try to pull fields out of frames rendered at only 30M temporally distinct moments per second, like this:

Your renderer must know that it is rendering 60M temporally distinct images per second.
Playing Back "Slow," or Synthesizing Dropped Fields
Two tasks which are relatively easy to do with frame-based data, such as old postage-stamp computer movie files, are playing slowly (by outputting some frames more than once) or dealing with frames that are missing in the input stream by duplicating previous frames. Certainly there are more elaborate ways to generate better-looking results in these cases, and they too are not so hard on frame-based data.When fields enter the picture, things get ugly. Say you are playing a video sequence, and run up against a missing field (the issues we are discussing also come up when you wish to play back video slowly). You wish to keep the playback rate of the video sequence constant, so you have to put some video data in that slot:

which field do you choose? Say you chose to duplicate the previous field, field 2:

You could also try duplicating field 4 or interpolating between 2 and 4. But with all of these methods there is a crucial problem: those fields contain data from a different spatial location than the missing field. If you viewed the resulting video, you would immediately notice that the image visually jumps up and down at this point. This is a large-scale version of the same problem that made the two-pixel-high line jump up and down: your eye is very good at picking up on the vertical "motion" caused by an image being drawn to the lines of one field, then being drawn again one picture line higher, into the lines of the other field. Note that you would see this even if the ball was not in motion.
Ok, so you respond to this by instead choosing to fill in the missing field with the last non-missing field that occupies the same spatial locations:

Now you have a more obvious problem: you are displaying the images temporally out of order. The ball appears to fly down, fly up again for a bit, and then fly down. Clearly, this method is no good for video which contains motion. But for video containing little or no motion, it would work pretty well, and would not suffer the up-and-down jittering of the above approach.
Which of these two methods is best thus depends on the video being used. For general-purpose video where motion is common, you'd be better off using the first technique, the "temporally correct" technique. For certain situations such as computer screen capture or video footage of still scenes, however, you can often get guarantees that the underlying image is not changing, and the second technique, the "spatially correct" technique, is a win.
As with de-interlacing methods, there are tons of more elaborate methods for interpolating fields which use more of the input data. For example, you could interpolate 2 and 4 and then interpolate the result of that vertically to guess at the content of the other field's lines. Depending on the situation, these techniques may or may not be worth the effort.
Still Frames on Video Output
By this point you've probably guessed that the problem of getting a good still frame from a video input has a counterpart in video output. Say you have a digitized video sequence and you wish to pause playback of the sequence. Either you, the video driver, or the video hardware must continue to output video fields even though the data stream has stopped, so which fields do you output?If you choose the "temporally correct" method and repeatedly output one field (effectively giving you the "line-doubled" look described above), then you get an image with reduced vertical resolution. But you also get another problem: at the instant you pause, the image appears to jump up or down, because your eye picks up on an image being drawn into the lines of one field, and then being drawn one picture line higher or lower, into the lines of another field. Depending on the monitor and other factors, the paused image may appear to jump up and down constantly, or it may only appear to jump when you enter and exit pause.
If you choose the "spatially correct" method and repeatedly output a pair of fields, then if there happened to be any motion at the instant where you paused, you will see that motion happening back and forth, 60M times a second. This can be very distracting.
There are, of course, more elaborate heuristics that can be used to produce good looking pauses. For example, vertically interpolating one field to make another works well for slow-motion, pause, and vari-speed play. In addition, it can be combined with inter-field interpolation for "super slow-mo" effects.
How Do I Show Video on the Graphics Screen?
Another permutation we haven't talked about is this: say you have some video coming into memory, and you want to show it on the graphics monitor (i.e. in a desktop application running on your progressive-scan computer monitor). For example, it might be the video capture preview window in an editing application.The simplest method is to use your favorite video capture library to capture already-interleaved frames (pairs of fields merged together into frames), and then display each frame on the screen at 30M per second using your favorite graphics library (e.g. glDrawPixels() for OpenGL, DirectDraw blit, etc.).
While this looks okay, it does not look like a video monitor does. A video monitor is interlaced. It scans across the entire screen, refreshing one field at a time, every 60th (actually 60M) of a second. A typical graphics monitor is progressive scan. It scans across the entire screen, refreshing every line of the picture, generally 50, 60, 60M, 72, or 76 times a second. Because graphics monitors are designed to refresh more often, their phosphors have a much shorter persistence than those of a video monitor.
If you viewed a CRT video monitor in slow motion, you'd see a two-part pattern repeating 30M times a second: first you'd see one field's lines light up brightly while the other field is fading out, then a 60th (60M) of a second later, you'd see the other field's lines light up brightly while the first field's lines were fading out, as seen in this diagram:*


If you viewed a CRT graphics monitor running at 60M Hz in slow motion, and ran playback software that used the simple frame-based technique described above, you'd see a full-screen pattern repeating 60M times a second. The entire video image (the lines from both fields) light up and fade out uniformly, as in:*


These differences in the slow-motion view can lead to noticeable differences when viewed at full-rate (keep in mind that our sample animations on the right are just crude approximations to what you'd really see). Some applications demand that preview on the graphics monitor look as much like the actual view on a video monitor as possible, including (especially) the jitter effects associated with using fields incorrectly. In some markets, customers want to avoid having to buy an external video monitor to verify whether or not their images will look ok on an interlaced video device.
Making video on a graphics monitor look like video is no easy task. Essentially, you have to create some software or hardware which will simulate the light which a video monitor would emit using the pixels of a graphics monitor.
Existing solutions to this problem fall into two general categories:
- Many PC graphics adapters have a "feature" which allows you to insert video directly onto the graphics screen. That video might be coming in live from a video input jack of the computer, or it might be coming out of a software or hardware decompressor (e.g. JPEG, DV, MPEG) playing a movie file or internet stream, but in every case the data is video, meaning that it consists of fields, not frames. The graphics adapter takes the responsibility to convert the field-based data into something nice on the frame-based graphics monitor. Further complicating matters is that the graphics monitor refresh rate might not even be 60M (or if it is, it may not be genlocked to the video source) so the graphics adapter may also have to drop, duplicate, or interpolate fields.
So how do these graphics adapters "convert" the data? It varies by device, but typically the image which is actually displayed on the graphics monitor contains the image data from the field which just came in, on the proper lines for that field. What is displayed on the lines of the other field might be black, or the result of evenly interpolating the adjacent lines from the field which just came in, or a previous field, or some fancier interpolation of these. These options provide various rough approximations to the appearance of an actual video monitor. You would choose black on the theory that the graphics monitor's persistence was close enough to that of a video monitor. You would choose an interpolated signal or the previous field on the theory that the graphics monitor's persistence was not close enough.
Nowadays, nearly every graphics adapter has this video insert "feature," even if the adapter has no video inputs, because it is used to "accelerate" the ubiquitous consumer application of DVD playback.
But, as you might guess from all the quotation marks I used above, this specialized hardware path comes at a very stiff development cost. The main cost is that you must generally engage very picky, vendor-specific, barely documented, specialized APIs to use the feature, and this wastes untold hours of development time. For example, in some cases there are arcane and arbitrary limits on the position of the video window that wreak havoc on GUI design and coding. If you just want to write code to play a DVD or forward live video to the screen unmodified, then there are high-level APIs to make this "easy," but if you want to actually manipulate the video, get ready for intense pain.
Another annoying side effect of the video insert "feature" is that, for many devices, the video pixels that appear on the graphics monitor are not really present in the framebuffer. This means you cannot read them out of the framebuffer with GDI/OpenGL/DirectDraw calls, and screen grab apps don't work. More seriously, it means you can't draw on top of the video (for example, when you pop another window on top, or overlay subtitles). Adapter vendors have come up with a myriad of hacks to work around this limitation, and these hacks add yet another layer of pain for the developer.
The hardware-based video insert "feature" is the de facto solution for live video monitoring and DVD playback, but it is often not worth the pain for more elaborate video applications such as those which edit and process video.
- Another solution which is sometimes available is field-aware primitives in your graphics API. For example, on several vendors' display adapters there is an OpenGL "interlace extension" which allows an application to do a
glDrawPixels() that only modifies every other line of a display. That is, an application gets images of each incoming field into memory at 60M per second, and canglDrawPixels() those pixels 60M times a second to a frame-sized region of the screen, in such a way that the graphics hardware moves down two framebuffer lines for every one line of the image being written. The intervening lines of the graphics framebuffer are not touched. This simulates a video monitor refreshing every other line of the picture at 60M hz. In slow motion, this technique looks like: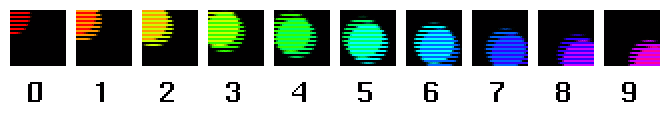
Of course, this method does not simulate the decay of the phosphors that are not being updated on each draw. You can also choose to clear the framebuffer between draws, which would be similar to the black option of the video "insert" feature described above.
There's an old page from the SGI Lurker's Guide called Displaying In-Memory Video Using OpenGL which may still be useful for modern OpenGL graphics adapters.
It's Not Even That Simple
This document has attempted to disillusion you from the assumption that you can treat field pairs as frames, citing the temporal difference between fields as the main cause for concern. Well, it turns out that in some cases, the temporal reality of video is even more harsh.The Reality of Cameras
It's now clear that when you capture a scene using a video camera, the fields you capture are temporally distinct. One question which we have not addressed until now is: how about the individual lines of data within a field—do they represent samplings of the scene from the same instant of time? How about the individual pieces of data along a given line of a given field?The answer to this depends on the kind of camera. Modern cameras use CCD arrays, some of which produce a field of data by sampling the light incident on a grid of sensors (throughout a certain exposure time) simultaneously. Therefore all of the pixels of a field are coincident: each pixel is a sampling of the light from a particular part the scene during the same, finite period of time.
Older tube-based cameras (which were distinguished by crusty old names like vidicon and plumbicon) would sample a scene by scanning through that scene in much the same way a video monitor scans across its tube. Therefore, in the fields created by such a camera, none of the data is coincident! Each "pixel" is from a different moment in time. Instead of capturing the crispy images which we presented to you above:
A tube camera would capture an image more like this:

Tube cameras are dinosaurs and are being replaced by CCD-based cameras everywhere. But it is still quite possible that you'd run into one or possibly even be asked to write software to deal with video data from one.
More importantly, it turns out that many modern CCD cameras, including those in smartphones, capture all the pixels on a line simultaneously (unlike scanning tubes) but capture lines separated in time (like scanning tubes). This generates cool rolling shutter / slit scan effects which can be artistic, annoying, or just confusing.
So even in modern data you are likely to see a version of the effects above and have to deal with it in your software.
The Reality of Monitors
A similar split exists in monitors. There are array-based display devices (e.g. LCDs) which change the state of all the pixels on the screen simultaneously or all the pixels on a given line simultaneously, and there are tube-based display devices (e.g. CRTs) whose electron beams take a whole field time to scan each line across the screen (from left-to-right then top-to-bottom). Obviously, tube-based display devices were in the majority but are losing out.When considering questions like how to photograph or videotape a computer monitor using a camera, this harsh reality can come into play.
However, because most of the flickering effects in interlaced video are due to local phenomena (ie, the appearance of data on adjacent picture lines), and because the temporal difference between samples on adjacent picture lines is so close to the field period, it is often the case that you don't have to worry about this harsh reality.
Other Types of "Fields"
"Segmented Field" Progressive Scan Systems
Certain video systems, such as 480i (e.g. NTSC), 576i (e.g. PAL and SECAM), and 1080i HDTV, are clearly field-based: a video camera that uses these systems will capture only half the lines of the image, and then, one field period later, capture the other lines of the image. The resulting fields are temporally offset. Furthermore, if you look at the electrical signal being sent over a video cable using a scope or a logic analyzer, you'll see the data for one field, and then the data for the next field.Other video systems, such as 720p and 1080/24p, are clearly progressive-scan. A video camera that uses these systems captures all the lines of the image simultaneously.* If you look at the electrical signal being sent over a video cable, you'll see all the lines being transmitted in one chunk, not segmented into two fields.
So far so good.
But it turns out that there is a third class of so-called "segmented field" systems, such as 1080pSF/24. These systems are really progressive scan, because again an entire frame is captured at one instant*, but when the frame is sent over the video cable, the data is segmented into two fields. That is, a piece of digital electronics in the camera buffers up the progressive-scan frame and slices it into two chunks of data for transmission over the wire. An innocent observer may be fooled into thinking that the data in each field is temporally distinct, but it is not.
Why on earth would someone make a video system like this? Ah, compatibility. It turns out that, early in the development of HDTV when VTRs cost USD $100,000, someone figured out that they could re-use a bunch of their existing field-based hardware (i.e. video switches, VTRs, etc.) with the new progressive-scan camera by faking the equipment into thinking that it was manipulating the old system.
While such chicanery will hopefully go the way of the dodo, it is quite possible that you may someday have to write software to deal with these "mislabeled" signals.
Spook Video Systems
For completeness, we should also mention that there are some other, very obscure video signal formats which are field-based, but have different kinds of "fields" from the ones we describe in this document.For example, so-called "field sequential" video signals have one field for each color basis vector (red field, green field, then blue field, for example) and those fields may or may not be temporarally offset from one another.
Basically, if you can imagine it, somebody (probably spooks) has implemented it! These systems are outside the scope of this document.
How Do I Interleave My Fields?
The process of weaving two fields together into their proper picture line order is generally called "interlacing" in the context of an electrical video signal or TV monitor, and "interleaving" in the context of software laying out lines in memory. The term "interleaving" must be qualified when used in this way, since it can also refer to how the samples of an image's different color basis vectors (e.g. R'/G'/B' or Y'/Cb/Cr) are arranged in memory, or how audio and video are arranged together in memory. We'll use the terms "interlacing" and "interleaving" interchangeably.Say you have two images in memory, representing two temporally adjacent fields from a video signal, and you want to know how the lines of those fields will weave together when the fields are played on a video monitor. Or vice versa: say you have an already-woven frame in picture line order in memory, and you want to figure out which lines will go out in which field and in what order.
This is the kind of thing you have to figure out every time you synthesize, manipulate, or display field-based video data.
Two Ways to Interleave
From a purely software perspective, there are two possibilities, case 1 and case 2:
In this diagram, one field is blue and the other field is pink. Each line of the diagram represents one video line of data. The vertical axis (n) represents the address of each line of video in your program's computer memory. So line n=0 is first in memory, followed by line n=1, and so on.
Columns 1a and 2a show your two fields separate (but abutted) in memory. For sanity, we assume that when you store whole fields in memory like this, you always store them in temporal order relative to each other. The T column tells you the temporal position of each line of video relative to the others. Notice how T goes from 0 to 4 in these columns, since each line of a field is already in temporal order, and the two fields are also in temporal order relative to each other.
Columns 1b and 2b show your two fields woven together into picture line order in memory. The S column tells you the spatial position of each line of video, as it gets displayed on a television monitor, relative to the others, where S=0 gets displayed on the top line of a television monitor, S=1 on the next line down, and so on. Notice how S goes from 0 to 4 in these columns, since the lines are in spatial order.
So, by reading the value of S in column 1a/2a, or T in column 1b/2b, you can figure out how to weave or un-weave your data.
Which Way?
So far, so good. But how do you know if you have case 1 or case 2?That's, well, the tricky bit...
If the video devices or libraries you rely on are properly designed, their API or documentation will just tell you directly. For example, if you're dealing with uncompressed data in QuickTime files, you can read one of the required ImageDescription extensions (which I designed for Apple) to get the answer.
If the answer isn't immediately forthcoming from the API or documentation, this is the point where people tend to give up understanding, and instead they "try it one way" and if that fails, "try it the other way." That method might work if you can guarantee that your video system (e.g. 480i NTSC or 576i PAL), video hardware, drivers, library software, and OS software are going to remain unchanged. I know a lot of people who've burned unbelievable numbers of hours putzing their code back and forth without knowing why the "field sense" keeps flipping around.
But it turns out that it's often not that hard to really get a grasp on what's going on, in such a way that you can predict and control for changes in the software that you rely on, so that your application always interleaves fields correctly.
You can achieve this in two steps:
- First, for each video system your software will support (e.g. 480i NTSC or 576i PAL), understand how the fields weave together in terms of the video line numbers found in that video system. That is, understand how interlacing works at the video signal level, independent of any capturing or playback hardware.
This is not hard, and it is the exact purpose of this document, which I recommend you check out:
Programmer's Guide to Video Systems
- Second, armed with that understanding, do a little research on the libraries and devices you depend on to find out which video lines they capture into memory, or play back from memory. Although you may not find this information in the manual, you will find that the tech geeks at your equipment company are very comfortable answering this question, because it's stated in exactly the terms they're familiar with—video line numbers from the video specifications.
Field Dominance
Another important, but very misunderstood, term in the video world is field dominance.Field dominance is relevant when transferring data in such a way that frame boundaries must be known and preserved. Examples:
- edits on a VTR or non-linear editing application
- GPI/VLAN/LTC/timecode-triggered capture or playback of video data
- interpretation of fields in a frame-sized buffer of video data for the purposes of interlacing or de-interlacing.
Field dominance can be "F1 Dominant" or "F2 Dominant." It determines the meaning of a "frame."
Review: What is F1 and F2?
F1 and F2 are the names given to each field in field-based video systems. As we explained in this section of our document about video systems, F1 and F2 are purely properties of the video signal. Specifically,- If you are looking at part of the waveform of a field-based analog video signal on an oscilliscope, you can tell whether it is from an F1 field or an F2 field by the shape of its sync pulses.
- If you are looking at an excerpt of a field-based digital video signal on a logic analyzer, you can tell if it's from an F1 or F2 field based on its sync words.
What is Field Dominance?
Field dominance determines how those fields pair into frames.For "F1 Dominant," a "frame" is an F1 field followed by an F2 field. This is the protocol recommended by all of the industry video specifications.
For "F2 Dominant," a "frame" is an F2 field followed by an F1 field. This is the protocol followed by several production houses in Manhattan and elsewhere for the 480i formats only. These production houses are numerous enough, and the miles of old footage captured by them are voluminous enough, that one day you may very well be called upon to handle F2-dominant materials.
What are the cases where the frame boundaries must be known, and thus where field dominance is relevant?
- Most older VTRs, and most video editing software, cannot make edits on any granularity finer than the frame. The latest generation of VTRs are able to make edits on arbitrary field boundaries, but can (and most often are) configured only to make edits on frame boundaries.
- Video capture or playback on a computer, when triggered by an external signal such as GPI or timecode, must begin on a frame boundary.
- Software must often interleave two fields from the same frame to produce a picture (e.g. "still frame").
- When software de-interleaves a frame-size picture, the two resulting fields are, by definition, from the same frame.
In the next sections, we'll explain what has field dominance, where it begins, what has to worry about it, and why it exists at all.
What Has Field Dominance and When?
The cause-and-effect of field dominance is often confusing. Think of field dominance as a property that video material can acquire when it is edited with other material or grouped into frames in a computer. Once some video material has acquired a particular dominance, it must be manipulated with that dominance from then on.Put another way,
- Video material is born when video fields come out of a video camera, a video signal generator, or a field-based computer graphics algorithm. At this point, there is no need to impose any frame boundaries on the material: it has no field dominance.
... F2 F1 F2 F1 F2 F1 F2 F1 F2 ... - Say at some point you cut out part of this material and edit or record it onto a video tape that has different, pre-existing material. Say that pre-existing material has no field dominance (for example, say it's all camera black). Assuming your VTR works in frames as almost all VTRs do, you have to make a choice: do you cut the new material into the pre-existing material on the tape at an F1 field or an F2 field?
pre-existing tape material ... F2 F1 F2 F1 F2 F1 F2 F1 F2 ... new material: F1 dominant edit F1 F2 F1 F2 F1 F2 new material: F2 dominant edit F2 F1 F2 F1 F2 F1 Once you make that choice, then the material on the tape acquires a field dominance. All subsequent edits to that material need to begin on the same field type.
To see why this is so, assume we have edited together material A, B, and C following F1 dominance:
F1 F2 F1 F2 F1 F2 F1 F2 F1 F2 F1 F2 F1 F2 A B C Now say we try and edit in material D to replace material B following F2 dominance:
F1 F2 F1 F2 F1 F2 F1 F2 F1 F2 F1 F2 F1 F2 before A B C material D D after A B D C We have created an unpleasant edit where one field of material B still pops up at the edit point. Field dominance is the protocol which video engineers invented to prevent this problem.
- Say you switch between two pieces of material that have no field dominance using a video switcher. The switcher has to decide on a field boundary to make its switch; it has assigned a field dominance to its output material.
- Say at some point you bring material that does not have a field dominance into a computer in such a way that pairs of fields are grouped into a frame. For example, say you are capturing DVC (DV) frames or uncompressed frames. You have to make a choice: do you set your device/library to F1 dominance so that it will group an F1 field followed by an F2 field into a frame:
video signal ... F2 F1 F2 F1 F2 F1 F2 F1 F2 ... frames ... frame frame frame frame ... Or do you set your device/library to F2 dominance so that it will group an F2 field followed by an F1 field into a frame:
video signal ... F2 F1 F2 F1 F2 F1 F2 F1 F2 ... frames ... frame frame frame frame ... Once you have made this choice, you have determined the boundaries on which the material may be edited. You have given the material a field dominance.
Even if your device/library is capturing seperate fields (e.g. M-JPEG field images), its behavior may be affected by its setting for field dominance. For example, the first buffer you get from the device/library after beginning the capture may be guaranteed to be the dominant field.
- Say you have video fields which came from somewhere other than a video input device (for example, that you just synthesized in software). You will still have to make a choice of field dominance if you want to store the fields into most common container formats, such as QuickTime or AVI. These is because these libraries group your fields into frames and their editing commands work on frame boundaries.
Who Has to Worry About Field Dominance?
Once material has a field dominance, all subsequent devices which edit that material must use the same field dominance, so that their edits never produce half-frame edits as shown with material D above. This means that you need either:- a way to set the dominance of VTRs, video switchers, computer video input devices (e.g. DVC/1394/Firewire, composite input dongles, ...), and computer video storage libraries (e.g. QuickTime, DirectShow), or
- some documentation from these devices and libraries which tells you which dominance they use.
Modern VTRs and switchers offer this option.
Many computer video input/output devices assume F1 dominance, meaning:
- When you begin capture, the first field captured will be an F1 field.
- When you output fields, the first field output will be an F1 field.
- If the video device gives you timestamps for incoming video frames, it will be the timestamp of that frame's F1 field.
- If the video device supports externally triggered (e.g. GPI, timecode) input or output, that transfer will begin on the first F1 field after the trigger fires.
Many computer video storage libraries/file formats, such as QuickTime and AVI when used with certain data formats, effectively assume F1 dominance, because they hard-code the spatial/temporal relationships of the lines of an F1 and F2 field (i.e., case 1 or case 2 above) to one possiblity for each video system. This could be considered a feature or a bug :)
Other storage libraries/file formats give you a choice of dominance, although it's sometimes not obvious that the choice you're given relates to field dominance. For example,
- QuickTime implemented an ImageDescription extension for M-JPEG video which tells you which of the two JPEG fields stored in each frame is on "top." Although this extension was created in order to handle different video systems (e.g. 480i NTSC or 576i PAL), it turns out to also be the thing needed to handle different field dominances within one system. This is because the fields always must be stored in the file in temporal order, so either an F1 or an F2 field may be first, and therefore the top line of the frame may be the temporally first or second one, as shown in our 480i field diagrams.
- When it came time to standardize uncompressed Y'CbCr video, we had the benefit of hindsight, and so I helped Apple design some ImageDescription extensions that outwardly acknowledged the issue of fields, standards, and field dominance.
Equipment which does not perform edits, such as a video monitor, a waveform monitor, or a vectorscope, does not care about field dominance.
Why Is Field Dominance Selectable?
You might ask: "Why didn't the industry just choose and use some dominance (F1 or F2, doesn't matter) so that we never have to worry about it?"Well, welcome to video! Presented with an arbitrary choice, video engineers are incapable of making the same decision. Some engineers decided that F1 should be the dominant field because the number 1 comes before the number 2. As we will see below, LTC and VITC timecodes are defined so that a new hh:mm:ss:ff occurs at an F1, so this meshes.
Some engineers decided that the dominant field should be the field that includes the top line of a picture (which, in turn, depends on how they sample the video picture!). In some cases this works out to be F2.
Who was the first to make a dominance decision? The Ampex VR1000B 2-inch quad video deck from 1962, on which people did edits by "developing" the tape's magnetic control track into visible marks using a chemical and then splicing the tape at those marks with a razor blade, placed its control track marks every thirtieth of a second at—you guessed it—the beginnings of F2 fields. This greatly predates timecode formats like LTC and VITC. So in some sense F2 dominance is right because it was first.
You might also ask: "Why doesn't the industry just choose and use something now?" The original culprit decks from the sixties created a legacy, in the form of reels and reels of archival material, that was passed on to each new generation of VTR technology as studios transitioned to "the next" equipment. This legacy is still alive; all decks sold today have switchable field dominance, and studios still have material from "the last" equipment with edits on a certain field boundary.
Another, even more grotesque idiosyncrasy of analog video tends to dwarf the field dominance issue anyway: color framing. Edits on older VTRs which did not fall on a 2-frame (NTSC) or 4-frame (PAL) boundary relative to the analog signal's color subcarrier would generate unattractive pops and instabilities in the image at the edit point. Therefore, people were too busy worrying about which 2- or 4- frame boundary they had to edit on to worry about which field they had to edit on.
Modern component digital decks and non-linear editing applications have a small chance of breaking the cycle: they have the ability to edit on arbitrary field boundaries, and they have no color framing idiosyncrasies. Studios might actually start editing on field boundaries, and the dominance issue will finally be dead. Editors will still have to maintain the alternation between field types though, since the fields are spatially distinct.
Field Dominance and 3:2 Pulldown
The issue of field dominance is further confused by 3:2 pulldown, a method of transferring 24 frame per second film images to the "60" field per second rate of 480i video. 3:2 pulldown is described below.Regardless of one's choice of field dominance, video generated through 3:2 pulldown can have video frames whose fields are from different film frames, possibly even different scenes of a film. So in a sense, the material has neither dominance, but instead has a repeating 10 field pattern. If 3:2 pulldown generated material is then edited without consideration of the 3:2 sequence, you get a sequence where scene changes occur at completely unpredictable field boundaries. This was a major issue for constant-angular-velocity consumer videodisks mastered from 24 frame per second footage, where customers wanted to achieve rock-solid F1/F2 still frames nomatter where they paused. CAV videodisks actually include a "white flag" marker in the vertical interval on all F1/F2 pairs that may contain scene changes, as a hint to the videodisk player not to pause there!
Fields, Dominance, and Timecode Signals
Over-the-wire and on-tape timecode signals such as LTC and VITC are described in Timecode. This section relates timecode with the concepts defined above.A LTC codeword is one video frame time long. As specified in ANSI/SMPTE 12M-1986, the start of a LTC codeword always coincides with a certain line near the beginning of an F1 field, regardless of the field dominance of the video material.
A VITC codeword (also defined in 12M) tags along with each video field. The VITC codeword has a "Field Mark" bit which specifies if the field is F1 or F2. A VITC codeword's hh:mm:ss:ff value always increments at a transition from F2 to F1, regardless of the field dominance of the video material.
So if your material is F1 dominant, then LTC and VITC behave as you would expect:
| field type | F1 | F2 | F1 | F2 | F1 | F2 | F1 | F2 | F1 | F2 |
|---|---|---|---|---|---|---|---|---|---|---|
| edits on tape | E | F | G | |||||||
| LTC on tape | 01:00:00:00 | 01:00:00:01 | 01:00:00:02 | 01:00:00:03 | 01:00:00:04 | |||||
| VITC on tape | F1 | F2 | F1 | F2 | F1 | F2 | F1 | F2 | F1 | F2 |
| 01:00:00:00 | 01:00:00:01 | 01:00:00:02 | 01:00:00:03 | 01:00:00:04 | ||||||
But if your material is F2 dominant, then LTC and VITC straddle your edit points like this:
| field type | F1 | F2 | F1 | F2 | F1 | F2 | F1 | F2 | F1 | F2 |
|---|---|---|---|---|---|---|---|---|---|---|
| edits on tape | ... | H | I | J | ... | |||||
| LTC on tape | 01:00:00:00 | 01:00:00:01 | 01:00:00:02 | 01:00:00:03 | 01:00:00:04 | |||||
| VITC on tape | F1 | F2 | F1 | F2 | F1 | F2 | F1 | F2 | F1 | F2 |
| 01:00:00:00 | 01:00:00:01 | 01:00:00:02 | 01:00:00:03 | 01:00:00:04 | ||||||
This means that one frame of F2 dominant material consists of two fields with different timecodes!
More Fun With Fields: 3:2 Pulldown
3:2 pulldown is a method of going between photographic film images at 24 frames per second and interlaced video images at 60 fields per second (actually 60M, but the difference between 60 and 60/1.001 gets handled by other hacks). It does not apply to 50-field-per-second signals. The method consists of a sequence which repeats every 4 film frames and 5 video frames (this chart assumes F1 dominance):| Film Frames | frame A | frame B | frame C | frame D | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Video Fields | F1 | F2 | F1 | F2 | F1 | F2 | F1 | F2 | F1 | F2 |
| Video Frames | frame 1 | frame 2 | frame 3 | frame 4 | frame 5 | |||||
This chart tells you which film image to use in order to produce each video field. The resulting video will then contain many fields which are duplicates of other fields in the sequence. It is often very interesting to tag the video stream with information indicating which video fields are redundant, so that agents which operate on that data such as compressors or video processors can avoid wasted effort.
The lurkers guess that it's called 3:2 pulldown because the pattern of fields you get contains sequences of 3 fields followed by 2. Or perhaps it's called that because 3 of the 5 video frames do not end up coinciding with the start of a film frame and 2 do.
Thoroughly Ambiguous: Avoid The Terms "Even" and "Odd"
These terms are ambiguous and terribly overloaded. They must be avoided or carefully defined where used."Even and odd" could refer to whether a field's active lines end up as the even scanlines of a picture or the odd scanlines of a picture. In this case, one needs to additionally specify how the scanlines of the picture are numbered (zero-based or one-based), and one must also say which lines of the video signal are considered active, which is not at all something you can assume.
"Even and odd" could refer to the number 1 or 2 in F1 and F2, which is of course a totally different concept that only sometimes maps to the above. This definition seems somewhat more popular.
| Support This Site | If you have enjoyed this site, here are a few ways that you can help me get time to expand it further: |
| donate now Use your credit card or PayPal to donate in support of the site. |
| Use this link to Amazon—you pay the same, I get 4%. |
| Learn Thai with my Talking Thai-English-Thai Dictionary app: iOS, Android, Windows. |
| Experience Thailand richly with my Talking Thai-English-Thai Phrasebook app. |
| Visit China easily with my Talking Chinese-English-Chinese Phrasebook app. |
| I co-authored this bilingual cultural guide to Thai-Western romantic relationships. |
| Copyright | All text and images copyright 1999-2023 Chris Pirazzi unless otherwise indicated. |
If you have enjoyed this site, here are a few ways that you can help me get time to expand it further: